PROJECT 5 (Multi-cloud Integration): ETL PIPELINE CLOUD INTEGRATION OF PYSPARK WITH AWS AND GCS
Why Multi-cloud?
The answer is Stability and Cheaper price. What do I mean by stability? Few years ago AWS which is known as the backbone of the internet was down for some minutes, Imagine the loss and inconvenience.
Also, using all services of a particular cloud service provider is costly (although more scalable).
Which is why “You shouldn’t put all your eggs in one basket”
 Dont put all your eggs in a single basket
Dont put all your eggs in a single basket
So I demonstrated how to build a simple ETL pipeline by using pyspark (spark SQL) with AWS (S3,RDS) and GCS (cloud storage, SQL) No bad feelings for Azure, but I just have to focus on the biggest two.
I made a visual representation of what I did here below.
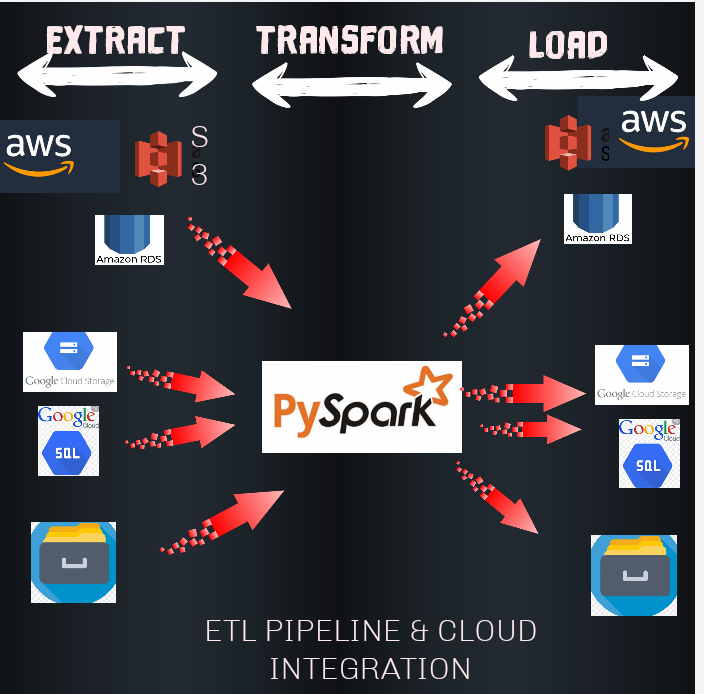 ETL pipeline and Multi-cloud Integration
ETL pipeline and Multi-cloud Integration
STEPS
Extract
There are many ways of extracting data from S3 bucket, RDS, Google cloud storage, google cloud SQL and local storage. Well, I used three major ways;
- Using Boto3 (AWS)
- Using Pyspark ingestion
- Using google cloud APIs
Before using any of these methods, it’s important to create an AWS and GCS IAM role and credentials. You can check here and here for how. After getting an IAM role, grant the role to use these services, and collect the access keys.
You can then insert these keys into Boto3 and google cloud APIs.
For Pyspark inbulit ingestion (read), it’s a different ball game and more complex as you would need to download a spark hadoop engine for either AWS or GCS ingestion.
The downloaded jar files would be inside the hadoop jars folders.
What makes it much more complex is that I used a Google colab linux environment.
I won’t be sharing the exact script because of the confidential keys and extended explanations, but you can check my github for something similar to it.
Transform
Once the data has been extracted, I used Pyspark SQl function to create new columns from the old ones, and also renaming them. Why spark sql? because it’s popular like pandas, I am much more comfortable using it for data manipulation.
Loading
Loading back is easier for S3, cloud storage and local storage. For RDS & Google SQL, I used Python interface for POSTREGSQL, i.e psycopg2 to write data into these databases.
Like I said earlier, check my github for the codes
THANK YOU