PROJECT 2 (analytics): SENTIMENT ANALYSIS OF SHOPRITE on Twitter
It’s important to put the client first, and try as much as possible to seek and understand there opinion about a product or service.
This project is aimed at analyzing:
- Tweeps (twitter user’s) emotion about shoprite
- Most occurring words in tweets
- Top Tweeps on ShopRite trend table.
 Word-cloud of shoprite-related tweets
Word-cloud of shoprite-related tweets
METHOD
- To use Tweepy API to scrape relevant tweets from twitter, (Unfortunately twitter restricted the maximum scrap tweets to 2-3000) (But I am going to revisit this project using tools like Selenium, Bs4 or scrapy).
- The tweets are parse using Regex&Nltk.
- TextBlob is used to analyze Sentiment polarity.
- While Seaborn & Wordcloud is used to visualize the analysis.
 Sentiment-Analysis
Sentiment-Analysis
-
DATA SCRAPING
Using Tweepy, I used my API secret keys and tokens to gain access to my twitter account. To get these keys, apply for developer mode on twitter which normally takes 48 to 72 hours to get. The tweepy query was modiifed to scrape 1,000 tweets related to shoprite in english. -
DATA CLEANING Text cleaning can be tedious, but with efficient use of regex, I was able to remove URLS and categorize scraped data into NAMES (tweeps), DATES, LOCATION and TWEETS in a DataFrame.
-
POLARITY ANALYSIS
Using TextBlob Library, the cleaned tweets was analyze to get the polarity & sentiment. The polarity range from -1 to +1
- -1 to -0.51 indicate ‘Very Negative’
- -0.5 to -0.1 indicate ‘Negative’
- 0 represent ‘Neutral’
- 0.1 to 0.5 indicate ‘Positive’
- 0.51 to 1 indicate ‘Very Positive’
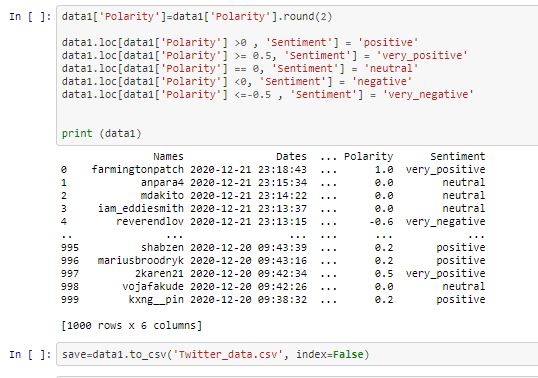 Polarity Analysis
Polarity Analysis
- EXPLORATORY DATA ANALYSIS
The chart below shows the top ten tweeps with tweets related to ShopRite
shoprite_sa 29
papizwane 7
p_phumo 5
destinychisom3 4
uchehone 3
shattachelsea 3
allie_phelan9 3
olivorang 3
ulstercounty911 3
marksun1962 3
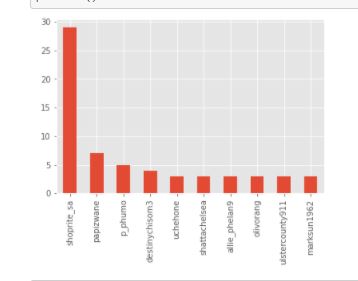 Top tweeps
Top tweeps
The next chart shows the frequency of tweets polarity, they range from 0 to 0.5. This indicate that most tweets are either neutral or positive.
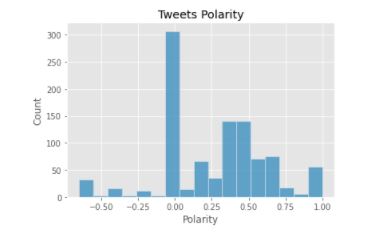 Polarity Frequency
Polarity Frequency
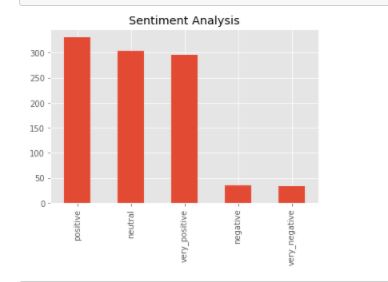 Sentiment Frequency
Sentiment Frequency
-
MORE TWEETS CLEANING
I used nltk library to tokenize(split) and remove stopwords(a,an,i, they…) from the texts. This is to enable the word_count analysis -
WORD_COUNT
Using FreqDist of NLTK library, The Top 50 words are:
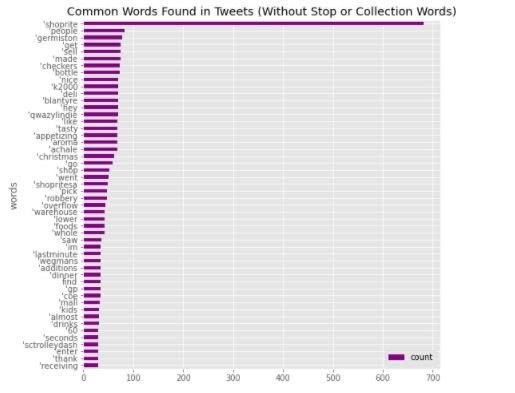 Word Count
Word Count
To make this analysis more apt, I used the word_cloud Library, which shows:
Word Cloud
CONCLUSION With insigths like this, Businesses would understand there customers feelings and be able to adjust, leverage and improve there products & services.
Check my github for source code
THANK YOU